Why Scraping Fails Silently (And Why That's Worse Than Crashing)
- Raquell Silva
- 3 hours ago
- 8 min read


A scraper that crashes tells you something is wrong. A scraper that fails silently does not. It returns a 200 OK status, the job finishes on schedule, and the dashboard stays green, but the data flowing into your systems is incomplete, stale, or simply wrong. This is the failure mode that does real damage, because nobody knows to look for it. At Ficstar, where we run more than 1 billion product prices through our pipelines every month, we have learned that catching silent failures is the hardest and most important part of delivering data a business can trust.
The reason silent failures are worse than crashes comes down to timing. A crash stops the pipeline before bad data spreads. A silent failure lets corrupted data move downstream into pricing models, inventory signals, and executive reports, often for weeks, before anyone notices the metrics have drifted. By then, decisions have already been made on bad inputs. This article explains how silent scraping failures happen, why they cost more than visible ones, and what an effective monitoring approach actually looks like.

What Is a Silent Scraping Failure?
A silent scraping failure is when a scraper completes successfully at the infrastructure level but returns incorrect or incomplete data. The job runs, fetches its URLs, parses the HTML, and exits cleanly. No error is thrown. The only problem is that the data it collected does not reflect reality.
This is fundamentally different from the failures most teams prepare for. Blocked IPs, timeouts, and HTTP error codes are loud. They trip alerts, page on-call engineers, and get fixed quickly. Silent failures produce none of those signals. As web data engineers, our experience is that the failures that hurt the business most are almost never the ones that announce themselves.
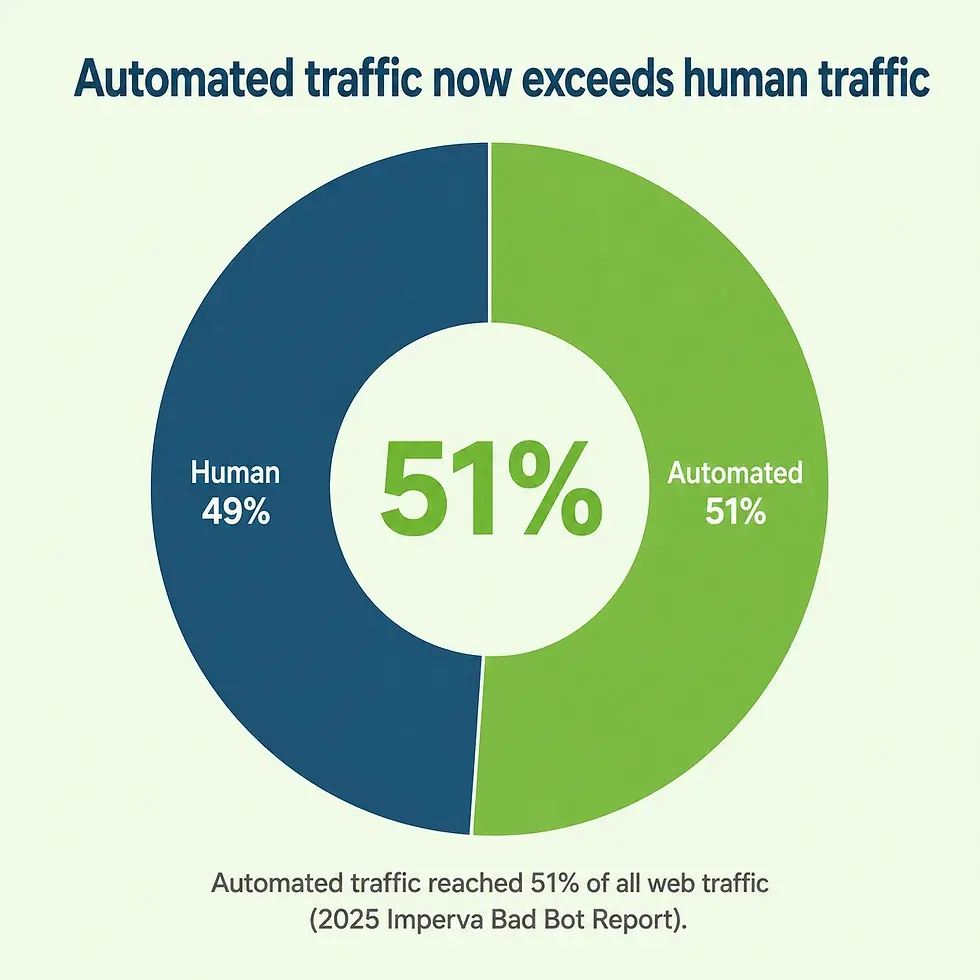
The danger grows as more of the web becomes hostile to automated collection. The 2025 Imperva Bad Bot Report found that automated traffic surpassed human activity, accounting for 51% of all web traffic. As anti-bot systems get more sophisticated to handle that volume, they increasingly favor quiet countermeasures over outright blocking, which is exactly what produces silent failures.
Common Causes of Silent Scraping Failures
Silent failures come from a handful of recurring problems. Each one leaves the scraper running while quietly degrading the data.
Selector drift after a site redesign. When a website moves a field or renames a CSS class, your selectors may still match something on the page, just the wrong element. The scraper extracts a value that looks real but isn't the intended data. A common example: after an HTML restructure, a product extractor starts mapping category names into the product title field. Everything keeps running. The data is garbage.
Bait pages and soft blocks. Many anti-bot systems avoid hard blocks because a clean 403 is easy to detect. Instead they serve truncated pages, placeholder content, or "soft 403" pages that look normal but contain no real prices or filler text. The scraper finds the elements it expects, throws no error, and collects dummy data.
JavaScript rendering gaps. When a site builds its content in the browser, a simple HTTP fetch returns only a skeleton. The data loaded by scripts or background requests never appears in the HTML. The scraper succeeds and returns empty or placeholder values. Even headless browsers hit timing issues, where the scraper reads the page before the real content finishes loading.
Proxy and routing problems. A misconfigured proxy pool can return rate-limited responses or cached, duplicate content without any visible error. Modern bot-protection systems often respond to a flagged IP with a normal 200 status and a page full of blank or decoy content, which the pipeline then ingests and stores as if it were real.
The thread connecting all of these is that the pipeline keeps running while the data decays. Most teams monitor whether scrapers are running, not whether they are collecting good data. A scraper can run perfectly while collecting complete garbage.

Why Silent Failures Cost More Than Crashes
A crash is a spike. A silent failure is an infection. The crash gets caught and fixed quickly because it interrupts the workflow. The silent failure spreads through every system that consumes the data before anyone realizes the inputs were wrong.
The clearest way to understand the difference is to compare them side by side.
Aspect | Loud Failure (Crash) | Silent Failure |
Detection | Immediate errors, 4xx/5xx codes, timeouts. Alerts fire. | No error, usually a 200 status. Looks healthy. No alerts. |
Data flow | Pipeline halts. No new data after the crash. | Pipeline keeps emitting records that are incomplete, stale, or wrong. |
Data quality | Bad data is prevented. At worst you get no data. | Bad data silently flows into downstream systems. |
Business impact | Caught and fixed quickly. | Decisions, models, and dashboards drift gradually on bad inputs. |
Monitoring needed | Basic uptime and job monitoring. | Field-level validation and anomaly detection. |
The financial stakes are substantial. According to Gartner research, poor data quality costs organizations an average of $12.9 million per year. Research published in MIT Sloan Management Review puts the revenue impact even higher, estimating that most companies lose 15 to 25% of revenue to poor data quality. Bad data is worse than no data, because no data forces a pause while bad data produces confident, wrong decisions.
The damage compounds at scale. A silent error rate of just 2%, when you are scraping millions of records a day, becomes a massive business loss. A pricing team adjusting products against stale competitor prices, or an inventory system that quietly stops detecting stockouts, can lose far more than the cost of the data collection itself. The cost rarely shows up at the scraper. It shows up later, in a budget meeting, when someone asks why a key metric moved.
Why Standard Monitoring Misses Silent Failures
Standard monitoring checks whether the job ran. It does not check whether the data is correct. Uptime dashboards, HTTP status codes, and exception logs all stay green during a silent failure, which gives teams a false sense of safety. Infrastructure success does not guarantee data correctness.
This is the gap between monitoring and observability. Monitoring answers whether the job ran. Observability answers whether the data still reflects reality. A scraper can be up, on schedule, and returning 200s while the data it produces has quietly stopped matching the source. Without checks that look at the content of each scrape, that mismatch is invisible.
The practical consequence is that silent failures get tolerated precisely because they do not interrupt anything. There is no incident, no ticket, no fire to put out. The data just flows, and the story it tells gets a little more wrong each day.

How to Catch Silent Scraping Failures
Catching silent failures requires validating the data itself, not just the pipeline that produces it. The hard part is rarely the repair. As Scott Vahey, Director of Technology at Ficstar, puts it: "The hardest challenge in fixing inaccurate data is identifying inaccurate data. Often the fix is the easy part." Effective programs layer several types of checks so that a failure that slips past one is caught by another. The approach below is the one we have refined across 1,000+ projects, and the principles apply whether you run collection in-house or work with a managed provider.
Validate Critical Fields on Every Run
Track the fields that matter most, such as price, title, and stock, on every page. If a field that is normally populated suddenly goes blank or fills with nonsense, flag it as a failure rather than passing it through. A missing price where a price used to exist is not an empty record. It is a problem to investigate. Logging records scraped, records failed, and errors encountered per run makes these patterns visible.
Watch Record Counts and Distributions
Compare each run's total record count against historical baselines. An unexplained drop, such as 30% fewer products than usual, is a strong signal that scraping is being silently blocked. Watching the distribution of page sizes helps too. A sudden burst of very small pages often means a bot is being served stub pages instead of real content.
Check Schema and Format
Run schema drift checks to catch changes in your columns or data structure, and use format validators on fields like prices, dates, and emails. If price fields suddenly arrive as empty strings or start including stray currency symbols, that is a sign the scrape has broken even though the job succeeded.
Use Canary Records
Maintain a small set of pages whose correct values you already know, then re-scrape them on every run. If a canary's scraped value diverges from its known value, you have caught a change in either the scraper or the target site immediately, at the source, before it spreads. A canary set is the cheapest form of ground truth available.
Monitor Trends Over Time
Single-run alerts miss gradual decay. Build rolling 7-day or 30-day baselines for metrics like daily counts, null rates, and value distributions, then alert on statistically significant deviations. Delayed detection is the biggest risk with silent failures, because slow drift looks normal without a baseline to compare against.
Taken together, these layers form a simple hierarchy: confirm the scrapers are up, confirm the fields are correct and complete, and confirm the trends and distributions are stable. The goal is to move past "is the pipeline running?" to "is the data accurate?"
How We Approach Silent Failures at Ficstar
When data feeds pricing decisions worth millions, "the job finished" is not good enough. Through two decades of running enterprise collection, the principle we keep returning to is that detection has to happen at the data level, before anything reaches the client.
On complex projects, every data file we deliver goes through 50+ quality checks before it leaves our systems. That validation combines three layers that each catch what the others miss: automated checks for completeness, format, and logical accuracy; machine learning models that flag anomalies and unusual patterns; and human analysts who apply judgment that automated systems cannot replicate. A price that is technically a valid number but wildly out of range is exactly the kind of silent error this catches.
We also treat website changes as a monitoring problem, not a reactive one. Our crawlers and source sites are watched continuously, and when a site changes its structure or anti-scraping measures, we update the affected crawlers before the change degrades data delivery. One of our enterprise retail clients put it plainly in a G2 review: their internal tools could not scrape complicated sites whose layouts changed constantly, but our crawlers stayed stable through it. When errors do occur, we rerun the entire collection rather than patching the output, which is why our team has been known to work after hours and weekends to correct a problem before a scheduled delivery. The aim is straightforward: you never receive data you cannot trust, and you never have to be the one who discovers the failure.
The Bottom Line on Silent Scraping Failures
The most expensive scraping failures do not crash. They hide behind green dashboards and quietly feed wrong answers into the decisions your business depends on. A crash is recoverable because you see it immediately. A silent failure poisons your data for days or weeks before anyone notices, and by then the damage is already in your pricing, your forecasts, and your reports.
The defense is rigorous observability. Validate the content of every scrape, run canaries and field-level checks, baseline your trends, and alert on any deviation from what reality should look like. In a data-driven business, it is far better to fail loudly and fix quickly than to whisper wrong answers that mislead your decisions.
If your team is making material decisions on scraped data and you want confidence that what arrives reflects reality, start your free trial and see the difference accurate, validated data makes.



Comments